バイオとITの研究者の出会いと共創 - さくらじまハウス2022-
はじめまして、COGNANOのIT部門でプロダクトマネージャーを担当しているsonodです。
2022年10月28日から29日の2日間にかけて、さくらじまハウス2022が鹿児島で開催されました。
2日間で、スピーカーとして24名、参加者は延べ約200名で、参加可能枠に収まらないほどのイベントになりました。このイベントの中で、COGNANOは、最終日の29日の最後のセッションで、代表の伊村さんとCTOのまつもとりーさん、モデレーターに株式会社マイナビの油井さんを迎え登壇しました。
今回は、このセッションのレポートをします。ITの業界で働かれている方々に、バイオとITが越境し融合した新たな挑戦について興味を持って頂くきっかけになると嬉しいです。
COGNANOのトークセッション

セッションタイトルは「技術は技術で終わらない、研究者の邂逅・見据える未来」です。
伊村さんとまつもとりーさんの自己紹介

最初は、登壇者の自己紹介から始まりました。油井さんの自己紹介が終わった後、CTOのまつもとりーさんの自己紹介があり、さくらインターネットで研究者をやりながら、COGNANOでは経営者でもあり、様々な経歴があることに対して会場の方々が興味を持っているように感じました。続いて、代表の伊村さんからの自己紹介は少し不思議な空気感でした。なぜなら、伊村さんはバイオの専門家で、以前は医者として仕事をされており、今はバイオスタートアップの社長であるため、その経歴がITのイベントで聴き馴染みのないものだったからです。しかし、油井さんが「伊村先生」と呼んでいたことに対し、伊村さんが「医者をやっていたこともあり、先生と呼んでもらえてると思うのですが、できれば、伊村さんでお願いします」と言ったことで、会場の空気も和らぎ、伊村さんの人柄が会場に伝わったようでした。
COGNANOの事業内容の説明

自己紹介の次は事業内容の説明に移り、COGNANOにとってアルパカが重要な役割を担っていることや、そのためにアルパカを飼育しているというお話をされました。医師として勤めていた経歴にも驚きがありましたが、会場の方々はアルパカを飼っている話に興味が惹かれているように感じました。そこからアルパカの話がしばらく続き、日本では色々な規制があり購入が難しく、アメリカのオレゴンまで購入しに行って、強面の人たちに交渉して18頭空輸してきた話で笑いが起こりました。しかし、アルパカを使った実験がなかなかうまく行かず、暗黒期に入った苦労話をされていました。バイオやアルパカの話など、IT業界ではめったに聞くことのない話を次々とされており、会場で聞くのは新鮮でした。
COGNANOが何を解決するどういうプロダクトを作っているのかという問いに対して、伊村さんは「ビジネスとしては、人類が今までデザインできなかったような薬を作ります。しかし、ビジョンとしては、人間や生き物を一つのシステムとして捉えて理解する。元気な時も病気な時もそれをシステムの問題として捉える。」と答えていました。続けて、今何ができていなくて、これができると何ができるのかというと問いに対して、「日々生きてる時ってシステムが動いていて、何も努力しなくても動いている。お腹が減れば何かを食べるといったように。そのシステムは、ブラックボックス化されている。こういったものを情報化して、自分の人生をログで把握できるようになる。生まれて生きて死んでいくということを自分の思いや概念だけじゃなくて情報として把握したい。」と話されていました。
僕は、人がまだまだブラックボックスで解明されていないことが多いという話は以前聞いていたのですが、これだけ時代も進み、IT化も進んできた中でも人のことはブラックボックスと言われるほど解明されていないことに驚いた記憶があります。また、この話の中で「人をシステムとして捉えてログで把握する」といったITに通じる表現をしたことが、とても興味深いと思いました。
プロダクトのビジョンの話に続けて、乳癌のマーカーの話になりました。マーカーとは、癌を診断するために、癌細胞の位置を特定するものです。バイオの業界では、このマーカーを用いて診断することが主流になっているそうです。その癌の中でも、人間が未だにマーカーを発見できていないトリプルネガティブ乳癌(TNBC)と呼ばれる乳癌があります。COGNANOは、そのTNBCに対して有効なマーカーを見つけ出したそうです。その時に、伊村さんは、「マーカーを見つけるのを人間がやっているからできないのではないかと思ってですね。これを、データから機械で深掘りする事によって、非常に深いところから抽出する事ができると考え、やってみたら上手く行けた。そこで、バイオデータがベースにはなるが、機械でサポートされなかったら結局わからないということをしみじみと悟った」と話されていました。
伊村さんは当たり前のことのようにこの話をされましたが、人類がこれまで発見できなかったTNBCのマーカーを発見したことは、今後多くの方の命を救える可能性があると思います。僕はもともと社会に対して貢献していきたいという気持ちがあったため、このようなプロジェクトに直接関われることが非常に嬉しく感じました。
このTNBCのマーカーは、実用化に向けてプロダクトを進めています。今後、乳癌以外の癌への展開も考えているので、引き続きCOGNANOをウォッチしていてもらえればと思います。
TNBCについて詳しく知りたい方は、こちらをご覧ください。
パネルトークや質疑応答

パネルトークの中から、僕が印象に残っているいくつかをピックアップしてお伝えします。
- なぜ、スタートアップや経営・組織に興味関心が向いているのか

「なぜ、スタートアップや経営・組織に興味関心が向いているのか」という質問に対し、CTOのまつもとりーさんが、「今まで沢山勉強してコードを書いたり論文を書いたりしてきた。OSSに貢献したり、作ったりして楽しかったし、使ってくれた人から声をかけてもらったりフィードバックをもらえることも多かった。しかし、それが直接的に社会や誰かの役に立っているかというと遠い距離を感じていた。1人で研究できることにも限界があるので、専門性の高い活動をチームや組織で取り組むことでその価値を最大化し、自分達の活動がもっと社会と近くなるように研究開発成果を世の中に届けたいと思い始めた。それをここ数年の目標にしている。」とコメントしました。僕自身も開発などを通じてサービスを世の中に出してはきましたが、これで社会に貢献できているのかということを考えることもありました。そのため、この思いには大変共感しました。
また、プロダクトマネージャー目線で見たときにも、1人でやる事と、チームや組織としての取り組みのバランスは常に意識する必要があります。プロダクトマネージャーは、ビジネスやUX、IT技術と言った広い範囲での知識が要求されます。しかし、1人で全てを行うことはできません。そのため、各スペシャリストが方向性に迷わないように、方向性を示しながら協力していけるチーム作りをしていくことが多いので、チームや組織で取り組むことでその価値を最大化するという点についても心に留めておきたいと思いました。
- 伊村さんとまつもとりーさんの出会いはなんだったのか

「伊村さんとまつもとりーさんの出会いはなんだったのか」という質問に対し、伊村さんから「ITのことを全くわからなかったが、闇雲にGmailでまつもとりーさんにメールしたのが最初です」という話をされていました。二人の出会いは、伊村さんからの突然のメールだったようです。しかし、コロナ渦中にあったそのメールは、売れそうだからコロナ検査デバイスを作るんだ!という風に聞こえてしまい、まつもとりーさんはすぐには信用できなかったそうです。ところが、伊村さんと会話をして行くうち、まつもとりーさんは「当時バイオのことは詳しくわからなかったが、伊村さんには、自分が質問したバイオのことは何でも分かりやすく納得できるレベルまで答えられる医学知識の深さがあった。そこから伊村さんを信用したと仮定すると、これから作ろうとしていたプロダクトの話も正しく感じてきたし、今まで人類が見つける事の出来なったTNBCのマーカーを、しっかりとデータがある状態で1年くらいで見つけてきた事実もあった。だから、細かいバイオが本当かどうかはわからなかったとしても、そこは伊村さんを信じるべきと思ったときに、そこから描いていた絵というのが、全部正しいいし、それが実現できると世界が変わりそうだと、ストーリーとして腑に落ちた」と話していました。これは後日、伊村さんが話していたことなのですが、まつもとりーさんも15年前からインターネットやシステムを生命のように捉えて研究してきた背景があり、イメージとしては「ウェブ認識と、生命システム研究の対比で、二人が反対側から歩いてきて、パンデミックの中で出会った」と言っていました。
これは、僕自身もとても感じていた話でした。僕がまつもとりーさんから話を聞いてCOGNANOへの参加を決めたときに、これが実現すると社会をよりよい方向に変えていけるという夢と期待を感じました。この気持ちは、僕がITエンジニアを始めたときに持っていたもので、医療などを通した社会貢献をしたいと思っていたところに、がっちりとはまった感覚でもあります。加えて、伊村さんから、COGNANOが保有するデータの価値や、目指しているストーリーを知ることで、ますます共感したことを覚えています。
- 別のパンデミックがあるかもしれませんが、日本はどんな準備ができるでしょうか。

「別のパンデミックがあるかもしれませんが、日本はどんな準備ができるでしょうか。」という質問に対し、伊村さんから「うちが準備できることだけ話します。ウイルスはどんどん変化していってますが、変化に対応できる創薬システムは今まで存在していないんです。だから、場当たり的な対応で薬を作ってきました。それを情報化できたら予測とか分析したりでトラックできるようになります。新しい株が出てもずっとシーケンシャルについていくトラッキングシステムを開発しています。」と回答されました。ここで、まつもとりーさんから「こう聞くと色々やれてる人がいて、その中の一つがCOGNANOのように聞こえるが、変異についていけているのは世界でもCOGNANOだけだったりする。その現実を目の当たりにしたときに、すごさというのを理解できる。」と話されていました。
この話は、COGNANOの重要な取り組みの1つになります。COGNANOでは、保有する膨大かつ高品質な抗体データに対して機械学習を適用することにより、ウイルスの変異をトラッキングできるシステムを開発しています。ウイルスの変異追跡とトラッキングについて詳しく知りたい方は、こちらのブログをご覧ください。
また、抗体についての説明と、機械学習については、こちらのブログをご覧ください。
セッション全体を通して
伊村さんとまつもとりーさんが二人とも強調して述べていたことは、人も生物である限りシステムであるという視点です。そもそも生命は未解明な現象が潜んでいるシステムで動いていて、知らぬ間に産まれて生きて死んでいきます。人体もシステムなので、設計図であるゲノムを解読すれば、多くの生命現象を理解できると思われていましたが、期待したほどの理解には至っていません。ここでのまつもとりーさんの「アナロジー的には、コンピューターで例えるとゲノムはカーネルのソースコードと考えられる。カーネルのソースコードを理解したからと言って、多層的かつ複雑に構成されているWebアプリケーションやシステムの挙動まで理解できないことに似ている」という追加コメントがあり、この解説を聞けば、ITエンジニア目線でとてもわかりやすいと思いました。
これ以外にも様々な質問やトークがありましたが、それはいずれ動画で公開できればと思っています。
まとめ
今回は、さくらじまハウス2022の参加レポートを書きました。このイベントを通して、生命の分子情報を共通言語とし、テクノロジーを介してバイオとITが越境し、融合していくことへの納得感や、COGNANOがやろうとしている事の革新性と面白さが伝わっていると嬉しいです。僕自身、改めて聞いていても、伊村さんとまつもとりーさんの経営や組織についての話を聞けて学びになりました。また、人も生物である限りシステムでありコンピューターに置き換えた考え方もできるという話を聞けたのは大変面白かったです。
これから我々は、今回お話ししたTNBCのマーカーやウイルスの変異をトラッキングできるシステムなどのプロジェクトを通して、世の中のすべての人たちがウェルビーイングに暮らせる世界を実現するために活動をしていきます。これからのCOGNANOの活動にご期待ください。
最後までお読みくださり、ありがとうございます。
関連情報
ホームページ
大量のバイオデータを活用するためのMLOpsの取り組みと課題
バイオとITの融合企業であるCOGNANOで主に機械学習の基盤整備を担当しているtokibiです。この記事では、私のようなソフトウェア開発を中心にキャリアを積んできたITエンジニアが、COGNANOでどのような業務を行っているかのご紹介もかねて、機械学習のワークフロー改善の中で取り組んでいる内容についてお話できればと思います。
COGNANOにおける機械学習の取り組み
COGNANOでは、アルパカが生成するVHH抗体の情報を元に教師データを作成し、抗原抗体の相互作用を予測する深層学習モデルを構築するという試みに取り組んでいます。2010年にVHH抗体の可能性に着目して以来、バイオチームでは長年に渡ってデータを収集してきました。アルパカという生体の免疫反応が反映された情報は、現在データ化されているだけでも3億ほどのレコード数に上り、機械学習に適用するにあたって十分な量が蓄積されています。機械学習に関するより詳しい解説は、研究開発を担当している同僚のつるべーさんが記事を公開しておりますので、ぜひ以下のリンクも併せてご覧ください。
MLOpsの実践に向けた取り組み
機械学習エンジニアとデータサイエンティストが、モデルの性能向上につながる業務を円滑に行えるように、ITチームでも環境の整備を通して支援していく必要があります。
MLOpsの導入について
機械学習におけるワークフロー全体の効率を向上させるための実践手法として、近年ではMLOpsと呼ばれる概念が現れていますが、COGNANOでもこのような原則に則りながら各プロセスの改善を試みているところです。
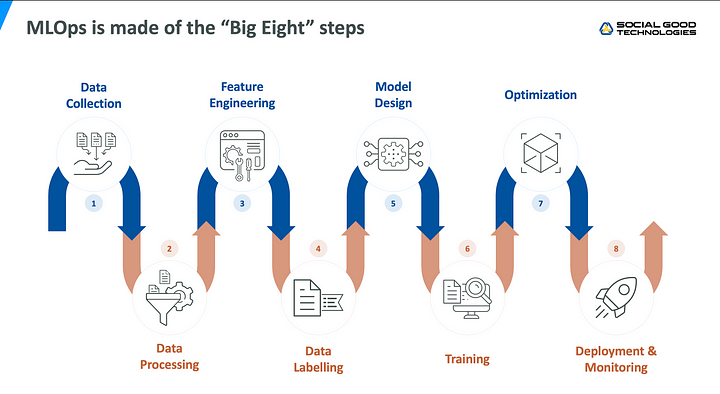
MLOpsは教師データのベースとなるデータの収集や前処理から、モデルのデプロイや運用開始後のモニタリングなども含めて対象とする総合的な概念ですが、今回は、その中の一部であるデータ前処理のプロセスに焦点を当てて、実際に行っている取り組みをお話したいと思います。
VHH抗体を対象にしたデータ前処理の前提
先程は「VHH抗体の情報を元に教師データを作成する」と一言で言ってしまいましたが、機械学習で利用可能な状態にするためには、いくつかの工程を経なければなりません。これには大きく分けると2つの工程が存在し、前半は次世代シーケンサーの出力に対する加工処理で、後半は抗原とVHH抗体のアミノ酸配列のペアに対して正解ラベルを付与していく処理です。
アルパカから採取した抗体遺伝子は、バイオチームによって行われる実験を経て次世代シーケンサーにかけられ、最終的にはFASTQフォーマットで記述されたファイルとして出力されます。この中には、読み取ったDNAの塩基配列と、各配列文字の品質スコア(確からしさ)が記載されています。
出力された直後のFASTQファイルには、不要な配列や品質の低い配列も含まれるため、はじめにアダプタートリミングやクオリティトリミングといった処理を行ったり、後続の処理のために塩基配列からアミノ酸配列に変換するなどの処理を行います。これらは cutadapt や Trimmomatic のようなバイオインフォマティクスの分野で活用されている複数のコマンドラインツールを組み合わせて実現しており、基本的には入力と出力を各コマンドで繋いでいくパイプライン的なプロセスです。

こうしたアミノ酸配列は、バイオチームによって行われる変異体(ウイルスの新型変異タンパク質など)を用いたバイオパニングの度に生成されます。COGNANOでは、バイオパニングによって作成された複数のアミノ酸配列群を独自のアルゴリズムで比較することで、抗原と抗体の結合の有無を検証してラベリングを行っています。ラベリングの詳細については本記事の主題から外れるため省略しておりますが、将来的に投稿される論文の中で解説される予定です。
現状の課題と今後の取り組み
ここまでにお話したデータ前処理のプロセスは、部分的に見ればある程度の自動化は行われていますが、ラベリングの一部では表計算ツールを用いて手動で行っている箇所もあります。また、実験によって新しい抗体情報が追加される度に、データの前処理を行い、過去の情報も含めて教師データを作成した上で、学習にかけて作成されたモデルの性能を評価するという一連の流れに関しても、それぞれの担当者が手動で行っているのが現状です。その中で浮き彫りになってきた課題と今後の取り組みは以下の2つです。
1. ドメイン知識とIT技術の融合
先に述べたワークフロー全体の課題の他に、個別のプロセスの中で使用されているパラメータや手法についても改善の余地があります。現在はバイオチームのドメイン知識を元に選定されていますが、より良い選択肢が存在する可能性は十分に考えられますので、将来的には網羅的な比較検討も必要になるでしょう。このような課題の改善に向けて、現在はMLOpsの前身となるDevOpsの原則に基づいて、次のような基本的な環境の構築から始めているところです。
- データの保管場所にクラウドのストレージを利用することで、アップロードなどのイベントをトリガーに必要な処理を呼び出せるようにする
- 実行環境をコンテナ化することで、再現性や可搬性を向上させる
- ワークフロー自動化のためのパイプラインを構築する
また、今後はモデル開発環境の整備や、パラメータおよび手法がモデル性能に与える影響の評価といった機械学習特有のプロセスに対応していく必要もあります。そのために並行して、Kubeflowのようなオープンソースのプロジェクトや、メガクラウドの各社が提供するMLOpsの実行を総合的にサポートするプロダクト等の導入も視野に入れています。
このようなプロダクトの導入にあたっては、処理をPythonなどのコードに移行することで、修正のイテレーションを回しやすくなる場面もあると考えています。現状、複数のコマンドラインツールに依存している部分に関しては、実行環境のコンテナ化という選択肢を取っていますが、必要に応じて実行方法の移行も進めていく予定です。
2. エンジニアがバイオに関するドメイン知識を習得すること
加えて、バイオ領域の知識の獲得も必要になると考えています。私自身はこれまでソフトウェア開発を中心に行ってきたエンジニアですので、バイオやバイオインフォマティクスの分野について専門的な知識を有しているわけではありません。そのため、各プロセスの改善に取り組む中で、処理の意図がわからない部分も多数出てきます。幸いにも、Web会議やSlackで同期、非同期を問わず専門家へ気軽に質問できる環境ですので、困ることはありませんが、細部の品質を上げて、より良い基盤環境を構築するためには、私自身も一定のドメイン知識を身につける必要があるでしょう。
COGNANOのバリューには「越境と融合」があり、互いの専門性を尊重しつつも、可能な限り歩み寄るという姿勢を重要視しています。これはバイオとITの領域を両者が越えようとすることに他ならず、そこから生まれる成果が大きな価値を生み出すと考えているためです。この記事で挙げている深層学習モデルの構築も、その中から生まれたものの一つです。現在進行中のプロジェクトを通じて、社会に対してより良い貢献ができるように、日々取り組んでいきたいと思っています。
まとめ
今回はCOGNANOにおける機械学習の前処理工程と、それをMLOpsの枠組みに当てはめていくための取り組みをご紹介しました。最後に社会貢献のような固い話を挟んでしまいましたが、私自身は日々楽しみながら未知の分野に関する学習を重ね、改善に取り組んでいます。
我々が現在利用しているデータセットや、前処理の詳細については、論文の投稿等に併せて公開する予定です。できる限り再現性を高めた状態で提供できるようにしたいと考えておりますので、興味をお持ちいただいている方は、楽しみにお待ちいただければと思います。
最後までお読みくださり、ありがとうございます。COGNANOに関するお話が何かありましたら、社長の伊村さんやCTOのまつもとりーさん、tokibiまでご連絡ください。
バイオマンのパンデミック戦記
はじめに
COGNANO代表の伊村です。まずは、今回のブログ本編を執筆した前田部長の紹介をさせてください。
ダイアモンドプリンセス事件を知った時、COGNANOは新型コロナ創薬に舵を切りました。以来、クスリ開発だけではなく、「ウイルス変異」を追跡するトラッキング創薬原理の開発や抗体情報巨大ライブラリの構築に向け、すでに2年以上プロジェクトを続けています。寝食を忘れ戦い続けたのが、研究開発部の前田部長です。遺伝子工学、タンパク質・抗体工学、構造学を武器に、新しい手法で切り込むバイオイノベーターです。
2020年9月には「1年後に出現することになるオミクロンにも有効な抗体」をすでに発掘していましたが、バイオジャーナルの査読に時間を費やし、論文が受理されたのは1年半後になりました。このブログではジャーナルのピアレビューシステムの是非には触れません。とはいえ今回の「アルパカ抗体」論文公開は良い機会ですので、2年間の振り返りをブログに記述します。前田部長は、論文の筆頭著者でもあります。
お疲れ様!と言いたいところですが、コロナは全く終わっていません。当然、バイオサイエンスと社会運用は同じではなく、一元的な解決は望めません。世間では「うんざりだ」という感覚と、先行き見えない不安で、どう向き合ったらよいか、肚を決められなくなっている印象があります。
その意味では、バイオ&ITテックとしてのCOGNANOがやるべきことはスタートからはっきりしています。ウイルス変異は人間の予想を超える以上、人類がデータと計算力でどこまで食い下がれるのか、そして、万一毒性が強くなっても対策が打てるのか、を突き詰めることです。今やCOGNANOでは、2年以上蓄積し続けた膨大な抗体データと計算力がお互いに強化し合う段階に入っており、ウイルスゲノム変異をトラッキングすること自体に数学的な価値があると考えています。これは、世界でCOGNANOだけが進めているプロジェクトです。
変異に対応する多様な抗体データは、変異型を認識する個体(ヒトであれ動物であれ)からしか取得できないのですが、ヒト抗体遺伝子の解読には次世代シーケンサ(NGS)が使えないので、ラクダ科動物経由でしか、大量の抗体情報をトラッキングできないからです。人類とウイルスの生存競争(生存協調?)の中でリアルに選択される相互変化(ウイルス変異と抗体多様性のデータペア)は、100年に一度しか得られない「自然が与えてくれた稀有なチャンス」です。宇宙研究者が、まれにしか観察できない超新星爆発のデータを取らない、という判断があり得るでしょうか?
前田が記述していますが、20年前のSARS-CoV1のデータを(部分的であれ)生かした米国のチームが抗体創薬における勝者だった事実が、厳格なルールを証明しています。目を逸らす人々に勝機は訪れないと、今回のブログは語っています。現在、オミクロンBA.5, BA.2.75(ケンタウロス)など変異が進行しており、その全てをトラッキングしながら通用する抗体をぼくらは探し続けています。今回の前田ブログは、バイオ開発者が振り返る貴重な記録になると思います。
それでは、前田部長の本編へどうぞ。
本編

正しい研究者の共通点
「正しい」バイオマン、特に生化学者には、共通の特徴があります。まず興味のあるタンパク質を精製することができます。精製したタンパク質には、予想通りの生理活性が認められます。ときには、タンパク質の結晶すら作れます。残念ながら、このタイプの「地道な」生化学者は、今や絶滅の危機に瀕しているかもしれません。正統なプロは他人が作ったタンパク質をつかいません。もとより、市販されているタンパク質など信じていません。生化学のエキスパートは、生体から精製されたものを至高のものとし、培養細胞から精製されたものを次善のものとします。ほかの生物種由来のタンパク質は、ヒト創薬を前提とする場合、適切ではないリスクや誤謬が増大します。現代でも職人技が要求される、神経を使う領域です。
プロであれば、未知のタンパク質―新型コロナスパイク―こそ、ベストの方法で挑みます。パンデミックがはじまり、世界中の生化学者たちが、スパイクタンパク質を精製する、という課題に取り組みました。これが「正しい」生化学の姿勢です。目的は、スパイクタンパク質を理解し、ウイルスを無力化することでした。
蓋を開けてみると、新型コロナウイルスの研究をリードしたのは2002年からSARSを扱っていたエキスパートでした。彼らは10年以上にわたる「旧型」スパイクタンパク質への経験がありました。そして、新型コロナスパイクタンパク質の精製と構造決定にいち早く成功しました。 当時アメリカでは感染者は出なかったにも関わらず、防疫部は「War」と表現しています。実は日本の感染防御部門も着目しており、当時の記載が残っています。バイオ脅威に対するセンスの違いは潜在しているかもしれません。
新型コロナに感染し回復した患者さんには、免疫応答によって、ウイルスを無力化する抗体ができています。精製した新型コロナスパイクタンパク質を使って、その抗体を集めることができます。その抗体を作る細胞(リンパ球)の遺伝子を解読することで、新型コロナスパイクタンパク質を無力化する抗体をリストすることができました。
英米では複数の拠点がシームレスに整備されていた
もっとも初期に成功したのは、米国英国の研究グループでした。なぜ彼らだけができたのかには、明確な理由があります。彼らは、エイズウイルスやエボラウイルスなどを無力化する抗体を見つける方法を、パンデミック以前から作り上げていたからです。患者サンプルをシェアできる態勢、リンパ球を分別(ソート)して遺伝子を解読する技術、抗体を大量に精製できるパイプライン、承認の透明性と使用に責任を持つ制度。これらのシームレスなインフラを整備していたのです。
後を追うように、同様の研究が世界数百のアカデミア、ベンチャーによって進められました。トップチームに追いつくことができた研究チームも欧米英にはありましたが、追い抜くことはできませんでした。そして、2021年11月26日の新型変異株(オミクロン)の出現後も「生き残った」のは、パンデミック以前から研究を続けていたグループだけでした。事実として、オミクロン変異型ウイルスも無力化できる抗体(市販されている製品)は、SARS-CoV1(旧型コロナ)に感染して回復した患者保存サンプルから発掘したものです(GSK社製ソトロヴィマブ)。やはり、20年にわたる経験の差を埋めることは、相当に難しかったのです。結果として、欧米英以外の地域では、ほぼワクチンや創薬の能力がないことが明瞭になりました。
成功を約束する経験とは
ここでいう「経験の差」とは、一体どのようなものでしょうか。いくつかの要素に分けて、捉えることができます。
- 新型コロナスパイクタンパク質の品質(生化学)
- 抗体免疫の遺伝子資産(抗体の遺伝子ライブラリ)
- 抗体のアミノ酸配列データの解析量(プログラミング)
- 実証実験の組み方(ウェットバイオ・ウイルスの扱い)
1. 新型コロナスパイクタンパク質は、少なくとも哺乳類細胞に発現させた特級品である必要があります。うまくいかなかった研究グループは主に以下のものを使っていました。
新型コロナスパイクタンパク質の一部に過ぎない、受容体結合ドメイン(RBD)。昆虫細胞で発現させたスパイクタンパク質。市販品。これらは創薬の成功率を低下させる原因となります。
2. 抗体を作る生物としては、回復した感染患者(ヒト)が至高です。次善は、ワクチンを打ったヒトや、感染または免疫した動物です。成功しなかった研究グループは、十分に免疫されなかった動物を用いたり、さらには免疫すらしていない動物のリンパ球遺伝子(ナイーブライブラリ)から抗体を見つけようとしました。
3. 抗体の優秀性は、どのくらい発掘(遺伝子ライブラリからのマイニング)に労力を注いだかに相関します。
患者さんから探しだせる抗体遺伝子の数は、世界最高の研究チームにおいても数十個が上限でした。研究用マウスからは百個のオーダーが上限です。一方で、免疫する動物にリャマ、アルパカ、ラクダを用いた研究グループは世界に10チーム程度あり、数万から数千万種類の抗体を探索することができたはずです。COGNANOではスパイクタンパク質を認識する抗体を3千万種類次世代シーケンサで分析して蓄積しています。ただし、この種の研究は始まったばかりで、世界でもようやく数チームが気づいたばかりです。私たちは莫大な抗体データを取ることができるようになった初めての世代ですが、データの次には「計算処理する」ためのITテクノロジーが要求されます。この先頭にCOGNANOは位置しています。
4. 最後に、発掘した抗体がウイルスを無力化するかどうか、実験的に検証してみなければなりません。
患者さんに投与して効果を見ることが至高の方法です。とは言え、人体で実験するわけにはいかないので、感染動物に投与する方法が次善の方法です。ミミック手段として、ウイルスに感染する培養細胞を用いる方法は、再現性良く定量的な方法です。しかしあくまで試験管内の現象にすぎない点に留意すべきです。
さらに大切なことですが、抗体がスパイクタンパク質のどの部分に結合するか(エピトープ)を知ることも、とても重要です。なぜなら、抗体がどの変異株に有効で、新型変異株に無効になるか、ロジカルにわかるからです。抗体がスパイクタンパク質に結合している様子を撮影する技術(クライオ電子顕微鏡)が、国内では今回大阪大学で稼働し始めたのですが、欧米では数年前からアカデミアと製薬が協力して標準的な作業になっていました。
成功したグループはどこも、当然のようにウイルス感染実験を行っており、かつ世界標準レベルでエピトープ決定を行ないました。これらの項目をシームレスに満たせる......ということが、勝者共通の能力であり、先進国で用意されたファシリティでした。
これら4つの要素を満たした研究グループのみが、登頂へ進むことができたのです。そして、オミクロン株の出現によって、敗れ去った研究グループには、それぞれに理由がありました。各グループが発表した論文をひもとくと、なぜ最善を尽くせなかったのか、行間にその理由が書かれています。ウイルスタンパク質製造に関して最善を尽くせず敗退した研究グループは8割以上にのぼります。加えて(ヒト・動物に)免疫しない方法から出発したグループで成功した例はありませんでした。
天国へ行ける者は、地獄への道を知り尽くしている者である
新型コロナウイルスの研究に限らず、「成功するチーム」はどれもみな似通っているものです。
古人曰く、
「天国へ行ける者は、地獄への道を知り尽くしている者である」
勝者は、10年前から、どうしたら失敗するのかを身を以て体験し、コストを払い、諦めなかったチームに限られました。結果として、勝者は英米(の会社とアカデミア)にほぼ限定されていました。以上が、パンデミックという名の戦争ではっきりした事実です。この課題を、私たちはどう受け止めるのか、真剣に考える時がきていると思っています。(前田良太・COGNANO開発部長)
アルパカ抗体×機械学習の取り組みと今後の可能性
COGNANOで機械学習に関する研究や開発を担当しているつるべーです。先日COGNANOでは、新型コロナウイルスに有効なアルパカ抗体に関する論文やプレスリリースを公開しました。テレビや新聞などでも広く取り上げていただいたので、「アルパカ抗体」という言葉を目にした方もいらっしゃるのではないでしょうか。この成果は、ワクチン接種したアルパカから生み出される膨大な抗体遺伝子のデータが鍵を握っています。このデータには非常に複雑かつ未解明な生命現象が潜んでおり、深層学習などの機械学習技術が絶大な力を発揮することが期待できます。今回は、現在COGNANOで進行中の機械学習に関する取り組みについて紹介していきます。
背景: 免疫反応と抗体医薬
COGNANOの取り組みをご紹介する前に、そもそも抗体って何?と言う方もいらっしゃると思うので、簡単に背景を説明します。
人間は、外部から体内に侵入してきたウイルスや細菌などの抗原から体を守るために免疫という防御システムを備えています。この防御システムでは、体内に侵入した抗原に対抗するために大量の抗体を作り出し、抗原に結合して排除しようとします。この抗原を排除しようとする働きを免疫反応といいます。一つの抗体は特定の抗原にしか反応しない特異性を持つため、侵入してきた抗原に対応した抗体が作られます。
この抗体を利用して、病気の予防や治療をおこなう薬が抗体医薬です。抗体の特異性を利用することで、特定の抗原をピンポイントで攻撃できるため、治療効果が高く副作用の少ない薬として注目されています。抗体とは、抗原に結合するという機能に着目した名称であり、その実体は多数のアミノ酸が鎖状に連なったタンパク質です。抗体医薬の開発において、ターゲットとなる抗原に対して特異的に結合するタンパク質(抗体)を探索することが重要な課題となります。
アルパカが生成するデータ
COGNANOが保有するデータはアルパカが生成しています。そう聞くと、なぜアルパカなのか?が気になった方も多いのではないでしょうか。その理由は、アルパカが持つVHH抗体は、人間などが持つ一般的な抗体と比べて構造がシンプルであり、次世代シーケンサーという実験装置を使ってデータ化できるからです。ここで言うデータとはアミノ酸配列のことで、20種類のアミノ酸が並んだものです。1つのアミノ酸は1文字のアルファベットで表記できるため、アミノ酸配列は文字列として表現できます。
それではどうやって特定の抗原に対して特異的に結合する抗体を探索するのでしょうか。答えは「アルパカ体内で起きる免疫反応を利用する」です。アルパカに対して抗原を注入すると、体内で免疫システムが稼働し、抗原に対抗するための抗体を大量に作り出します。この抗体を取り出してデータ化していくわけです。さらに、COGNANO独自の手法により、取り出した抗体の中から実際に抗原に結合する抗体と結合しない抗体をラベル付けします。これがいわゆる機械学習の正解ラベルになります。実際のデータ化の過程やラベル付けはもっと複雑ですが、これらの詳細は今後論文として公開する予定です。
データの内容をおさらいすると、ターゲットとなる抗原のアミノ酸配列(文字列)、薬の候補となる抗体のアミノ酸配列(文字列)、および抗原と抗体のペアに対して結合する/しないのラベル(二値)があります。そのため、抗原・抗体のアミノ酸配列を説明変数、ラベルを目的変数として、結合の有無を予測する二値分類の機械学習モデルを構築できます。さらに、機械学習を専門とする者からの観点として、このデータが機械学習、特に深層学習の強力な学習能力を発揮する対象として、望ましいいくつかの特徴があります。
1. 膨大なデータ
あるデータに深層学習を適用する上での基本的な問題として、データ数が十分でないということがよくあります。この場合、どれだけデータの質が高くても、そこから有益な情報を取り出すことは難しくなります。
アルパカという生きた計算機は非常に優秀ですので、一つの抗原に対して膨大な数の抗体を作り出し、我々はそれをデータ化します。具体的には、データの処理の条件にもよるのですが、一つの抗原に対して、数十万〜数百万オーダーで抗体遺伝子の情報が得られます。さらに、複数の抗原に対してデータ化することで、膨大なデータを生み出すことができます。
2. 密なデータ分布
アルパカから得られた抗体はアミノ酸配列の類似性(相同性)が高いものを多く含みます。つまり、配列の大部分は一致していてほんの一部のアミノ酸だけが異なるといった抗体が得られます。これは抗原と抗体の結合を捉えるためには非常に有用な情報となります。機械学習の観点から見ても、一般にデータ密度が高い領域はモデルの予測の性能や信頼性が高くなります。
3. 免疫反応の法則性が潜んだデータ
我々のデータはアルパカの体内でリアルに起きている免疫反応の結果を反映しているため、データの中に何かしらの法則性が内在していると考えられます。もし法則性がなく抗体がランダムに作られるとしたら、2で述べたような類似性の高いアミノ酸配列は得られないでしょう。抗体のアミノ酸配列の長さをNとすると、取りうるアミノ酸配列の数は20のN乗個になります。しかし、生体内で起きている免疫反応という世界は実はもっと狭く、同一の抗原に対する免疫反応は有限通りである可能性があります。これであれば、なんとか深層学習で捉えられるかもしれません。このようにデータの裏側に捉えるべき真の現象が潜んでいるというのは、深層学習の適用先として非常に魅力的です。
深層学習により広がる可能性
タンパク質を構成するアミノ酸配列のデータに対して深層学習を適用する研究が盛んに行われています。興味深いことに、アミノ酸配列は文字列として表現できるため、最近の研究では自然言語処理の分野における技術の発展が急速に取り込まれる傾向にあります。具体的には以下のような研究があります。どちらも2018年にGoogleが提案した言語モデルであるBERTをタンパク質のアミノ酸配列に適用した研究です。
我々も独自のアルパカ抗体のデータに対して、TransformerやBERTなどの自然言語処理分野で発展した深層学習の技術を適用して研究を進めています。
我々が深層学習を用いて解きたい直近の課題は主に二つあります。一つは特定の抗原と抗体が結合(相互作用)するかを予測することです。このような深層学習モデルが構築できると、ターゲットの抗原のアミノ酸配列が既知であれば、COGNANOが保有している膨大なアルパカ抗体の配列との結合を予測することで、抗原に結合する抗体のアミノ酸配列をスクリーニングできます。結合するからといって必ず薬として有効であるというわけではありませんが、薬となる候補を計算機のみで絞り込めることは、創薬プロセスの大幅な効率化に繋がります。
もう一つの課題は、抗体が抗原のどこの部位に結合するかを予測することです。抗体が特異的に結合する抗原の部位のことをエピトープと呼びます。一般にエピトープは数個程度のアミノ酸からなる小さい領域であるため、エピトープの予測は抗原に特異的に結合する抗体を設計する上で非常に有益な情報となります。この課題は、近年機械学習の分野で盛んに研究が進められている機械学習の解釈性の観点からアプローチできます。特に、LIMEやSHAPを始めとしたモデルの予測に対する入力特徴量の貢献度を提示する手法は、エピトープの予測にそのまま活用できます。このような機械学習の解釈性についての最新の研究をエピトープの予測に取り込むことは非常にチャレンジングかつ実用的な研究です。
COGNANOだからこそできること
ここまでで述べたアルパカの抗体遺伝子のデータを用いて深層学習のモデルを構築する取り組みは、前例がなくCOGNANOだからこそできることです。その理由は単純でデータが唯一無二だからです。COGNANOではアルパカ抗体に着目して以来、その可能性を信じて疑わず、長い年月をかけて試行錯誤を繰り返しデータを蓄積し続けてきました。そもそも高度なバイオの実験スキルがなければデータ化すること自体が困難です。一方、先にも挙げた既存研究の多くは、強い仮定により正解ラベルをつけたデータやシミュレーションにより仮想的に生成した少量のデータを用いています。そのため、データの量の観点でも質の観点でも大きな優位性があります。どれだけ高度な深層学習のモデルがあっても、優れたデータがなければ、価値のある実用的なモデルを作ることはできません。
生体内の免疫反応の法則性が潜んだ我々のデータから有益な情報を取り出すためには深層学習や統計解析などの数理的なアプローチが必要不可欠です。データを単に人間が目視で眺めても何もわかりません。COGNANOでは、バイオの専門家のたゆまぬ努力により生まれたデータに数理的なアプローチを適用したことで、データの価値を引き出すことに成功し始めています。その成果の一つが新型コロナウイルスに関する論文であり、このような取り組みはこれからさらに加速していきます。ぜひこれからのCOGNANOにご期待ください。
まとめ
今回はCOGNANOの機械学習関連の取り組みを紹介しました。我々は、アルパカにターゲットとなる抗原を注入した際に体内で起きる免疫反応を利用して抗体遺伝子の情報をデータ化します。さらにこのデータに深層学習を適用して、特定の抗原に結合する抗体の予測や、抗体が特異的に結合する抗原の部位の予測に取り組んでいます。より具体的な研究内容は今後論文として公開していく予定です。
最後までお読みくださり、ありがとうございます。COGNANOに関するお話が何かありましたら、社長の伊村さんやCTOのまつもとりーさん、つるべーまでご連絡頂ければと思います。
IT系投資家にCOGNANOの考えをはじめて言葉にできた日
サポートいただいている地元行政の勧めで、エンジェル投資家向けのピッチしてきました。その様子をYoutubeで公開していただけることになりました。人生3回目のピッチです。
本エントリの下部に、発表に利用したスライドと登壇動画を公開します。スライドや動画に興味ある方はすぐに下部に行っていただければ閲覧可能なのですが、そこに至るまでの苦悩や自分の中で考えて考えて行き着いた方針について書いてみました。できればお付き合いくださると幸いです。
長年、学会発表はしていましたが、パンデミックの中でスタートアップの代表になって2年、「ピッチってなんだ?」まだよく分かりません。人気起業家の登壇やSteve Jobsがアイフォンを発表している映像も見てみました。あまりしっくりきません。
なぜ、聴衆は熱狂しているのだろう?ピッチを面白いトークショーと感じる人たちがいるらしい。逆に言えば、「Steve Jobsなら、絶対すごいことを言うはずだ」と思えるツボが確かにあり、そこに投げ込めばピッチは成功する。ただ、ぼくが訴えるべき相手は、COGNANOのファンじゃないし、アイフォンを買ったりアップルに投資したいと待ち構えている人々ではない。わざわざ暑い日に京都で話を聞いてもいいかな、と出向いてくれた見知らぬ人々にとって、つまらない話に聞こえたら失望されるに違いない。お互い、あまりに業界も興味も違うはず....
一般に、バイオってよくわからない、わからない話は面白いはずがない。どうして遺伝子や細胞を操作すると病気が治るロジックになるのか、理屈を追えばざっくり1時間はかかるだろう...いやいや、バイオむずいわ、どころの話じゃなく、自分の身に置き換えても、アイフォンの何が凄いのか、ぜんぜんわからなかった。ガラス画面で操作しやすい携帯電話だと、最近まで思っていた。バイオの何がどう凄いのか、説得はもっと難しい。それを10分で語れたら、Steve Jobs超えじゃないか...心は折れそうでしたが、すでにスタートアップの経営者であるぼくは、前に進むしかありません。
半年前、ピッチに初めて登壇して以来、会場を見渡して疑問に思ったり、気づいたことがありました。箇条書きします。
- 投資家の目線はどうやら明確に、IT系とバイオ系に分かれているらしい。金額も人数も圧倒的にIT系に投資意欲が集中しており、バイオ系は少数派であるらしい。
- IT系登壇者は若い起業家であるのに、バイオ系の登壇者は、ほとんど大成した方や教授風である(その証拠にスーツを着ている)。
- バイオ系のスタートアップは構造的に「すでに売上や利益が出ている」ケースはないので、「どれだけ専門家に認められているか」と言う説明が中心になる。
そのため、いきおい、すでに受けた投資、受賞、論文、特許の羅列になっている。
バイオマン出身とはいえ、ぼくらはスタートアップなんだから、ピッチ構成自体も、他人の真似ではなく、イノベートした方が良いのではないか(IT系の人はハックと言うのでしょうか?)...そこで、プロダクトやテクノロジーの説明ではなく、「どうして人々はバイオに投資しようと思わないのか?」を、水面下のテーマにしようと決心しました。人類にとって、医学創薬はむちゃくちゃ重要なのに、なんでつまらなく感じてしまうのか、すぐに儲からないと言う理由だけなのか、もしかすると、ぼく自身の振り返りになりそうな気がしたからです。
とは言うものの、いきなり意識が明確になったわけじゃなく、2年前からITエンジニアの人々(まつもとりーさんやゆいさん)と長時間会話してもらったことが大きく影響しています。バイオの基礎知識がほぼ共有できない状態で、でも分ろうとしてくれる人々に、どう言えば届くのだろう?「わからない」ことを諦めではなく、新しい可能性として昇華できる可能性はないのだろうか?その背景には、直感的に「この人たちの言うことは聞かなきゃいけない」と言う、リアリティーというか迫力のようなものを感じている自分がいて、それを頼りに会話を続けてきました。確かに、それは今や、体のどこかに蓄積しています。教えられたのは、一言でいうと「どんな世界を良いと思うのか?から逃げるな」ということだったかと思います。いずれにしろ、これはなかなか厳しいリクエストです。
加えて、地元行政からご紹介いただいたビジネス系メンターから、とても親切に指導いただいたことも幸運でした。投資家が何を求めているのかを考えろ、でも、今言えないことは仕方ない、ただし、その欠落意識を保ち失神するな、という教訓と理解しています。こちらも「逃げるな」です。
ピッチは、分かりやすく楽しいものじゃなきゃ、誰も聞いてくれない。そして登壇する限り、リアルから逃げない覚悟がいる。そう言う気分で、このたび、10分少々の登壇に臨みました。後で録画を見せてもらったら、滑舌が悪くカッコよくないのですが、内容的にはなんとか言いたかったことが言えたと思います。
楽しんでくださったら幸いです。
スライド
動画
「アルパカ抗体」に関する論文解説とCOGNANOはもうITテックになっています、の件
2年にわたる新型コロナ研究が、学術論文として受理されました。COGNANOの前田開発部長(筆頭著者)が主導して発表した論文です。
先日、京大チームからマスコミ報道をお願いし「アルパカ抗体」で拡散していただきました。
Webニュースメディアでも沢山言及頂きました。
- アルパカ抗体がコロナ全変異株に有効 京大などの研究チームが発表 - ライブドアニュース
- アルパカ抗体 新型コロナ全変異株に有効 京大など 2年後実用化へ - 産経ニュース
- アルパカ抗体が変異株を抑制 研究 - Yahoo!ニュース
どのようにして2020年に(パンデミックが始まって半年以内に)万能抗体を作れていたのか、ジャーナリストから質問を受けました。簡単には「アルパカ体内で起きる免疫反応を巨大情報として取り出すことができ、計算処理によって最適化に成功した」という答えになるのですが、口頭でお伝えするのは難しく、理解いただけたか自信がありません。というのは、質問者は医学関係であり、数学やマシンラーニング、IT領域は分野が違いすぎるので......自分自身そうなので他人ごとではありませんが。
今回のブログは、前田論文を解説します。パンデミック以降、世界中で抗体が作成されましたが、変異に対応できたのはCOGNANOだけです。(注:変異型が出てから、新たに作り直した、という対応例はあります)これは、試験管から物質を開発するだけでなく、とうとう生体現象が情報化されて直接プロダクトに結びつく時代に入ってきた、という流れを示しています。生体の現象を直接反映する方法としては、コロナ患者さんからヒト抗体を抽出するという流れが一方にあり、COGNANOの方法と双璧をなしています。新型コロナ創薬の実例を辿りつつ今までのブログも合わせてお楽しみいただけると思います!
薬の作り方
まずは、どのように薬(候補物質をシーズと言います:ちなみに改良した物質はリード)が開発されるのかを説明させてください。どんなクスリでも、標的分子に結合することで効果を発揮します。COVID-19の場合は、ウイルスが生存増殖するための酵素活性を低分子化合物で阻害するか、あるいは、ヒト細胞の受容体に結合侵入する現象を、サイズの大きい抗体でブロックするか、の2つの戦略に分かれます。
低分子の場合
- 多数(億単位)の低分子化合物やその派生物(デリバティブと言います)が合成されて製薬会社の倉庫に、権利とともに山積みにされています。
- モデル培養細胞などにシーズ候補を投入して、効果をチェックします。
- 期待できるシーズが見つかれば、より効果が高そうで、しかも副作用が少なそうなリードに改変します。
- 実験はロボットで高速化できますが、それでもナン億個の物質をやみくもに探索することは困難であり、情報化が期待されていました。この課題の解決を狙って、低分子を標的分子に対し嵌め込みシミュレーションする「予想企業」がすでに起業していて、先行例は北米ベイエリアのAtomwise社です。
- そこに登場したのがDeepMind社のAlphaFold v2.0と言えるでしょう。どんな標的分子も、高次構造を示してくれますので、便利になりました。しかし、AlphaFold v2.0は既知のタンパク質構造を機械学習して予想するので、ランダム変異によって創出される抗体の構造はわかりようがないし、新型コロナのSPIKE変異型も(ランダムかつ既報データが少ないので)ほとんど構造予想できません。
通常抗体の場合
- 抗体を作ってくれる特殊な細胞(ハイブリドーマ)を、マウス、ラット、ヒトから作成し、標的分子に結合し、かつ機能を発揮するもの(クローンと呼びます)を、培養細胞や試験管内の分子間相互作用チェックで探します。
- 標的部位(エピトープ)にコンタクトする抗体部位(パラトープ)を改造するのは困難です。
- 10年前のSARS-CoV.1患者から抽出された抗体遺伝子を再構築してデザインしたGSK(VIR)のSotrovimabは、オミクロンBA.1まで効いていました。これは、リアルな生体現象をそのまま利用した例として、優秀だったといえます。
アルパカナイーブライブラリからのVHH抗体(ナノボデイ)作成
- VHH抗体開発チームのうち世界で半数くらいは、ナイーブライブラリからVHH抗体を作成しています。ナイーブライブラリとは、屠殺したラクダ科動物からワクチンなしに採取した、大量の抗体遺伝子配列情報のプールから、有効な抗体を探索する方法です。
- プールには、生物が体験したことがない標的(例えばSPIKEタンパク質)に結合する抗体は、ほとんど存在していません。しかし、わずかに結合活性を示すクローンが1兆〜100兆分の1くらいの確率で偶然見出されることがあります。
- 結合確率の低さを補うため、SPIKEタンパク質全体ではなく、ヒト受容体分子ACE2にコンタクトすると言われている小さな部分(RBD: Receptor Binding Domain)だけを使用します。SPIKEタンパク質全体を用いると、ノイズが大きくなりすぎ、実験が難しくなるからです。
- 性能を高めるために、酵素によって遺伝子変異をランダムに挿入します。抗体の改良です。
- 動物操作がないので作業が早く、安上がりですが、数クローンの候補を提出するのが限界です。
- これ以降は、低分子の培養細胞スクリーニングと同じステップになります。
- パンデミックで、世界から10本以上のナイーブライブラリ論文が出ましたが、武漢型RBDを元に開発に着手した場合、ベータ型くらいまでの対応が限界で、変異型に対する対応能力が低い特性が示されました。また、薬効濃度指標であるIC50も、動物免疫を行う下記プロダクトと比べると1〜2桁劣っています。
アルパカ免疫を用いたVHH抗体作成:従来法
- アルパカ免疫の方法で世界10ラボほどから、優秀なVHH抗体が公表されました。
- SPIKEを標的とする抗体(を作るリンパ球)が、体内で幾何級数的に増加します。採取した抗体遺伝子からVHH抗体(ナノボデイ)を作成します。継続的にリンパ球を取ることが重要なので、動物を殺しません。
- 生物が抗体遺伝子を組み替える原理はわかっていますが、最適化のルール(アルゴリズム)はブラックボックスです。毎日、およそ1兆(1012)個のリンパ球が、SPIKEタンパク質に対する防御を目的として遺伝子を組み替えているわけです。理論上、1頭のアルパカは2ヶ月間で1020回以上の試行をおこなうはずです。
- 標的に結合する強さを指標にして選択することをバイオパニングと言います。まず結合性を担保するわけです。バクテリオファージに発現させる方法と、酵母に発現させる方法があります。
- これに合格した抗体遺伝子を元に、実際の物質を作成し、96ウェルの培養細胞などを用いてクスリとして効くものを、2次選別(スクリーニング)します。
- 基本的にはウイルスが変異したらゼロからやり直すことになる点は、ナイーブリブラリ法と共通です。なぜなら、多くのチームは動物に免疫するワクチン、あるいは結合標的として用いるベイトとして、簡便なRBDを選ぶからです。RBDでは変異に対応するには限界がありますが、とはいえ巨大タンパク質であるSPIKEを用いると、ウェット選択の作業量が膨らみすぎ、現実的ではないからです。
COGNANOの挑戦
生体免疫反応の一部しか利用しないVHH従来法を「抗体遺伝子」の情報化によって改善したのが、COGNANOの方法論です。莫大な情報を扱うので、巨大天然物であるSPIKEタンパク質に対する抗体群の全体像を俯瞰できます。
- 動物免疫を行う点では共通ですが、根本的な違いは2つです。
- 候補抗体遺伝子のデータ母数は、バイオパニング(結合保証)後だけで3千万リード(次世代シーケンサで解読したカウント)を超えています。
- このうち、ITチームが厳選した情報最適化クローンだけを、京大病院と提携してチェックしました。(ウイルス実験は規制エリアでしかできません)
- COGNANOが提示した12個のうち4個が変異型を克服していました。結果として、ウイルスを用いる危険な実験は12クローン分だけですみました。
- ほとんどの抗体はSPIKE変異で効かなくなるのに、COGNANOが創出した抗体は効き続ける理由を追及しました。このため、大阪大学・JEOL・BINDSチームとの共同研究で、クライオ電子顕微鏡を用いた立体構造解析を行いました。SPIKE変異はワクチンを回避する方向に誘導されると考えられ、イタチごっこになっています。COGNANOが創出した抗体P86は、ヒト抗体が届かない狭い隙間に刺さっていることが判明しました。

図の説明
3千万リード(次世代シーケンサで解読したカウント)のデータからITエンジニアによって厳選された抗体P86は、SPIKE3量体の隣り合うRBD同士の間隙に突き刺さるように結合していた。オミクロンのアミノ酸変異を赤で示す。P86は赤いエリアを避けて結合している。この狭い空間にはヒトの通常抗体は侵入できず、ウイルスが進化圧を受けない「保存された構造=弱点」に結合する抗体であることがわかる。このようにSPIKE複合体高次構造を認識する抗体は、RBDをマテリアルとするチームには開発できない。
方法論まとめ
|
|
従来抗体法 ハイブリドーマ |
VHHナイーブライブラリ法 |
COGNANOオリジナル (ヒュージライブラリ法) |
|
動物免疫(ワクチン) |
する |
しない |
する |
|
候補母集団数(機能スクリーニング対象数) |
102〜3程度 |
1〜10 |
107〜8程度 |
|
スクリーニング法 |
試験管チェック |
候補が少数なので候補選別に至らない |
マシンラーニング(ML) |
|
抗体の改善方法(最適化) |
基本的に不可能 |
ランダム変異挿入 |
最適化は生体内で実施済み;必要に応じ改変も |
|
kD(解離定数) |
10−7〜8M程度 |
10−7〜9M程度 |
10−10〜11M程度 |
|
未知の変異対応 |
ゼロから開発し直す |
ゼロから開発し直す |
ライブラリから機械採掘 |
|
エピトープ予想 |
不可能 |
固定したRBDのどこか |
MLにより変異後も予想可能 |
|
作成時間 |
3〜4ヶ月 |
3〜6ヶ月 |
ビッグライブラリ作成に5ヶ月、以後の対応は1ヶ月 |
ふりかえりとあとがき
バイオチームとITエンジニアチームが、共通言語で協力して初めて、このような成果を出すことができました。計算力を持たないチームにとっては、巨大情報は宝の持ち腐れであり、数年前まで自分自身迷走していたことはブログに書いたとおりです。また、AI創薬の記事でよく出てくる「構造シミュレーション」と異なるのは、COGNANOの場合は、「エビデンスとラベル付き」のリアルデータから出発している点です。アルパカのマザーデータは、試験管ではなく、実際に哺乳類のカラダで起きていたことです。これほど確かなものはありません。
AlphaFoldなどの機械予想では、SPIKE3量体変異のようなランダムで複雑な対象は、リアルタイムには追跡困難です。生体の免疫監視機構は、はるかに精密であると言えます。かけがえのない生体情報をそっくり取り出して、ML、ひいては、IT技術によって活用する...これがCOGNANOが提案する、かつてない方法論です。じつは、ワクチンを打ったボクたちにも同様な免疫反応が起きているのですが、ヒトの抗体遺伝子は複雑すぎて容易に観測することができません。アルパカ遺伝子を解読するまでは、自然の知恵の一部しか、取り出せていなかったのです。
長い説明をお読みくださり、ありがとうございます。
さて、ここまで読んでくださった方には、最適化アルゴリズムってどんなの?をお示ししないと消化不良になるかもしれませんので、MLチームが論文準備に入っています。こちらもどうかお楽しみに!
バイオテックCOGNANOの新CTOがITエンジニアである理由
今回は、まつもとりーさんを取締役CTOとして迎える理由、そして、ぼくたちが何を目指すのか、という考察をしてみます。
地球と人間の問題の多くはバイオ
人生は、言語、宗教、教育、金融、交通、通信、エンターテインメントなどのアート(人が作り上げたシステム)によって実現するとして、アートは、エネルギー、生命、食料、材料素材などのネイチャー(自然の事物)に立脚します。地球に補給される唯一のエネルギー源は太陽光であり、光合成は光エネルギーを固定するための優れたメカニズムです。化石燃料は太古の動植物の炭素からできており、光合成とCO2は太陽エネルギーのバッファーだから、地球の運命に直結して当然です。ゆえに食料もエネルギーも、人類生存にとって重要なネイチャーの多くはバイオ問題といえます。ヒトが宇宙に進出する時も、ロケット開発よりバイオ問題の方が重要かもしれません。ところが、生命という謎のシステム理解に、人類は難渋してきました。生命は、宇宙をみわたしても地球以外みつからない特別な存在であり、また複雑です。30億年の歴史を持つ地球生命に、抗体遺伝子という暗号(コード)を切り口にして挑戦しているのが、COGNANOです。
一方、ウェブは人が作った世界(アート)だったのですが、いまやウェブ自身が自律性やリアリティ(すでにバーチャルではない)を持つ世界に進化しているようです。まつもとりーさんの眼には、ウェブ世界が生命性を獲得していくありさまが映っているとのことでした。どうやら、アートだったウェブは、ネイチャー(っぽい方向)に向かうらしい。もしウェブが生命体なのだとすると、発生から30年にして、すでに大きな進化を遂げているわけで、バイオでは絶対に見ることができない「リアルタイムに進化を目撃する」ことが、ITエンジニアには当たり前の日常であるはずです。
25年前、頭に浮かんでいたイメージがありました。丘の上から、100万のバイオシティーを眺めて、その全てを把握することは可能か、という問いでした。

その問いには、イエスと答えることができるようになりました。ではいま、ITエンジニアと共に目指すべきビジョンは?
膨大で多様なバイオ情報を認識する方法論
それは 「進化するように」生命認識が自動生成していく世界 ではないかと思っています。
VHH抗体は物質であるばかりではなく「巨大情報」です。この世に1,000万種の生物がいて、それぞれ10〜1,000万種のタンパク質を発現しているとすれば、地球上には1〜100兆種類(1012〜15)のタンパク質、つまり抗原が存在することになります。ところで20種類のアミノ酸でコード化される抗体配列の組み合わせは、少なくとも(次世代シーケンサで判読できる配列の範囲だけで)2050通りの可能性がありますから、全生物の分子情報をカバーする「ウルトラサーバ」として、すでに十分です。たとえば、新型コロナの変異α, δ, ο型をカバーする全VHH抗体配列を帰納的に解読したら、「ウイルス変異に対応する獲得免疫の構成」を演繹的に理解することができます。今回のパンデミックにおいて、たくさんの有用抗体が報告されましたが、COGNANOは独自の視点から、変異するウイルスに対して演繹的認識に到達し、オミクロンにも効き続ける抗体を報告しています。以下がその論文のプレプリントです。
https://www.biorxiv.org/content/10.1101/2021.10.25.465714v1
ぼくたちの認識のスタイルは、アルパカから湧き出しウイルス変異と紐付けできる(帰納法的な)抗体配列情報と、マシンラーニングによる分子間相互作用の演繹的セオリー発見の、両者のキャッチボールから産まれるものです。この認識単位が、COGNANOのエンジンです。実用的には、次の変異が来ても各論対応ではなく、インシリコで迅速に創薬予測できるようになったりします。従来のバイオでは、各論の「成果」が得られれば、充足する場合がおおかったのでした。なぜなら、演繹的セオリーに至るためには、標準化された膨大なデータが必要で、取得することは不可能だったからです。

COGNANOの生命認識エンジン
COGNANOでは、計算科学によって「未知のがんマーカーを発見する」などの認識単位も積み増しています。COGNANOのマシンラーニングチームは、複数のユニット稼働の結果、帰納的なデータがなくても、最適解を機械が予言するようになる日が来ると考えています。人間でいう「仮想法(Abduction)」に似た創発、つまり「経験してないのに(個別実験もしてないのに)わかってしまう!」が起きるようになります。
また、VHH抗体を検知ツールとして使用すれば、ウイルス感染や心筋梗塞など様々なパーソナルモニタリングが可能となり、IoTとして役立てることができるようになります。この意味は、カルテやアンケートや画像などの情報ではなく、分子データが、直接的なサービスに使用されるようになる、ということです。実用化においては、量産化や標準化にすぐれた点を活かし、VHH抗体は有用物資になります。つまり巨大情報(ソフトウェア)であると同時に、そのまま有用物資(ハードウェア)としても使える、バイオでは稀なケースです。
さて今回のパンデミックでは、治療ではなく「適切な判断をしたい」だけなのに、PCR検査場や病院に並ばなければならなかった……外来はコロナかどうかわからない患者でいっぱいになった……どこか違和感がなかったでしょうか?「戦時中だから」不便でも不平が言いにくかったのかもしれない。安全と医療の情報が、検査動線のどこかで混線しているのかもしれない。
21世紀後半の人類は、病院任せにしていたヘルス(感染症、がん、遺伝、疲労、寿命、精神状態などなど)を自分でチェックできるようになった。難しいバイオ知識もスマートスピーカーが教えてくれるようになった。小型デバイスで取得された情報は、スマホを経由して匿名で集積されるようになり、70億人分のデータが同時に解析されて、人類の健康という無形資産は増大した
ここに書いたシナリオは、まだまだ「知恵と工夫が未来を創る」式の世界観に基づいています。今後ヘルス情報の扱いは、さらに個人にシフトするでしょうし、増大するユーザ情報は、より深く正確なフィードバックをもたらすようになるでしょう。本来あるべき姿だし、そこに大きなビジネスが生まれるのは確実です。
新しい認識は新しい世界観を生み出して行く
でも、まつもとりーさんたちと一緒にやろうとしていることは、もっと長射程のビジョンです。ぼくたちは、自動生成的に意識変容が起こるような気がしているのです。パンデミックを体験したぼくたちの世代はもう、「スペイン風邪」のように天変地異で済ますことはできない。なぜなら、ぼくたちは生命理解へのプローブを手にしており、しかも、ウイルスも人間も、共通の生命原理のうえで存在していることを、既に知っているからです。バイオの視点が変われば、お金や消費や環境も、すこし違って見えるようになるかもしれない。今だって、ヒトは病気になれば、健康と命が一番だと感じてしまう、か弱い存在です。気がつくと、まつもとりーさんはじめCOGNANOに集まりつつあるITエンジニアとそんな話をするようになっていました。
資本やエネルギーが世界のあり方を変えるように、バイオが世界のあり方を変えていく。ひとりひとりの生命認識が集まって、集合知として生成されていきます。VHHデータはネイチャーそのものです。創業以来、COGNANOはネイチャーから学んでアートの方向に引き寄せ、演繹的な価値を抽出することができるようになってきました。これからは、ネイチャーに忠実でありつつ、それを超えて新しい世界観が生まれる時代に入って行きます。生命観は進化し、デジタルネイチャーと言えるものになるかもしれません。そのような認識が生まれる空間はウェブであるはずです。準備は整いました。
これからのCOGNANOにご期待ください!
バイオなのにITの会社になる、だけじゃなく、ITなのにバイオできるチームになる!生物情報のデジタル化によって、バイオとITの融合を進行中