あるかないかわからないモノ:バイオ限界(前編)
COGNANO テックブログA, No.5
COGNANOのいむらです。
前回まで、「対象の多さに阻まれるバイオの限界」について書きました。全身40兆個の細胞で、基本の遺伝子だけでも3万種類が働いている生物を、まるっとわかりたいんですけど、、、、しかし一気に観るのが難しく、分解して1種類の遺伝子だけ、1種類の細胞だけ、掘り下げるバイオの方法についてでした。すると膨大な時間がかかってしまう。
今回は、「因果関係というセンスが作ってしまうバイオの限界」についてお話しします。がんを例にして、、、
がん細胞
がんとは、「数と配置が無秩序になるために、不都合をもたらす細胞群」のことです。細胞の社会では「調整ルール」があるらしく、細胞たちは「行儀よく」増えたり減ったりして棲み分けているので、ぼくたちは安泰です。日常、血液や皮膚は高速で入れ替わっています。がんの場合は、「過剰増殖」で周辺を圧迫するばかりか、「転移」というロケーションミスで、制御不能になっていきます。がんは、「細胞社会のシステムエラー」であることは間違いないでしょう。本当は、がんを含む細胞社会をまるっとわかりたいわけです。
なにが原因?ここから、根深い問題になります。A→B、というのが、因果関係の基本です。がん(B)の原因は、きっと遺伝子(A)でOKだよね。「がん細胞」というワルモノの正体を知りたければ、原因の遺伝子を解明すればいいよね、、、え、ちょっと待ってください、それでいいの?
がんは必ず、本人が「知らない間」に「体のどこか」に、できますよね?
- 時間軸問題
- 空間軸問題
2つの基本問題に答えるのはとても難しいのです。
がんは、いつからできたの?1年前?5年前?まさか、産まれる時からあったの?どんなふうに「今日見えているがんのかたちになったのか?」最初からマルチな細胞の組み合わせでスタートしたかもしれないし、また、一種類の細胞から始まって分岐した可能性もあります。時系列を順番に観察できないことが、がん研究の大きなハードルです。
空間軸を考えると、もっとわからなくなります。空間的に考えると、「がん細胞」っていうけれど、本当に1種類なのか?周辺の細胞は異常状態に加担していないのか?その場合、周辺細胞は「がん」といわないのか?いずれも明確な説明はありません。写真は、乳がん細胞株(実験室で培養できる患者由来の「がん細胞」)SKBR3です。見てしまうと、「お、これががん細胞か!」と思ってしまうのが人情です。こいつをやっつければいいんだな、というわけです。しかも多くの場合、その考えは間違いではない。

COGNANOが開発した免疫細胞CAR-TがSKBR3をアタックしている
あまり仮説を広げると研究が成立しなくなるので、これまでは、「とりあえず単一種類と仮決めした、ワルそうな細胞」の研究に限定するしかありませんでした。敵兵士を一人捕まえて、敵軍の全貌を尋問するようなやり方ですね。がんの研究は、時間軸や空間軸において、じつは「仮」設定でスタートしています。これが第一の限界です。
遺伝子が原因なのか?
一般に、がんは遺伝子異常が原因だと言われますが、本当でしょうか?数十年前、ある遺伝子をゲノムに導入したらがんになることがわかり、「がんの原因がわかった!」と言われたものでした。確かに、ほとんどの場合がん細胞は遺伝子変異を伴っており、「遺伝子異常は重要だ」というのは間違いないところです。がんになりやすいか、アナタのゲノムで検査してみましょう、というキャッチフレーズの商品がありますが、この響きは「がんの原因は遺伝子だ」というゆるい了解?に基づいています。とは言え、これらの検査は「がん化アクセル」とか「がん化ブレーキ」のような影響因子を評価しているだけで、がんとは何なんだ?を指摘できたり、診断できるわけではありません。実際、次世代シークエンサが発達したこの15年ほど、たくさんの患者細胞が遺伝子解析され、様々な異常が指摘されましたが、「これが原因だ」と断言できる統一理論はみつかっていません。この経緯は、3つの可能性を示唆しています(注:個人的考えです)
- がん細胞といっても、じつは一種類ではなく、高度に多様化しているかも。知りたい要素が分散し、バックグラウンド化しているため、容易に掘り出せない?
- がん患者サンプルには、初期に存在した重要な特徴がすでに消滅している?
- 遺伝子異常は期待したほど寄与していない。遺伝子以外の要因も大きく関与している?
これらの問題が多層構造になっているなら、容易には解明できません。これが第二の限界です。3課題に対し、次のような解決が考えられます
- →がんと周辺の細胞をしらみつぶしに調べ、微小情報を拾い上げる:平均値をとるのではなく、シングルセルのゲノム解読作業を、例えば100万個の細胞に関して実行。ビッグデータで検出力をあげる
- →発生時のがん細胞は残っていない:タイムマシンが発明されないかぎりお手上げ
- →遺伝子以外の高分子にも調査対象を広げる:脂質や糖鎖のデータ化は大変すぎ、情報化できるカテゴリーは現状では遺伝子しかないが、、、、

生命は、糖鎖、脂質、タンパク質、核酸から構成されており、物質としては、いづれかを解析することになる。それを元に現象を理解するのが分子細胞生物学の方法論。4物質のうち高速に情報化できるのは、今のところ核酸(遺伝子)だけ。一方、タンパク質の重要な特性である「構造」は難関であったが、AlphaFold2がアルゴリズム予想に到達したことは記憶に新しい。リアル構造解析はそれくらい大変だった。糖鎖や脂質はさらに困難。
因果関係という迷路
1の作戦は、これまでの方向性に間違いはなかったが、検出感度が足りなかった、という仮説に基づきます。IT系の方にはピンときますよね。「機械なら検出できるかも」です。deep miningにより、未知の「見えにくかった」ファクターが掘り出される可能性があります。すでにプログラマーがこの方面の研究を主導しています。ただし注意すべきは、「遺伝子変異が高度に寄与していた」という仮説に依存していることです。
2は苦しい課題で、過去に遡ってのリアルサンプルは入手できない。因果関係は、時系列がわからない場合、格段に難しい問題になります。初期の特性が、すでに失われていたら・・・・ほぼ現実味がない。
3、遺伝子以外を対象とするには、どうすればいいんでしょうか?それは、タンパク質や糖鎖を、がんとリンクすることを意味します。さあCOGNANOどうする?後編に続きます!
ITエンジニアから視える景色に立ってみる(後編)
COGNANO テックブログA, No.4
COGNANOのいむらです。ITエンジニアから視える景色に立ってみる(後編)です。
今回は、ITエンジニアのまつもとりーさん、つるべーさんに出会うまでを、、、
バイオマンが視ている景色
バイオは夢中になってウェット実験をする文化なので、(本当は必要だったのに)久しくエンジニアと接点がありませんでした。論文(PubMed)検索やメール以外の用事を感じない環境で暮らしてましたね、、、
遺伝子物質はDNAだとわかって以後をワトソン・クリック時代と呼んでいいと思いますが、バイオ研究は遺伝子ベースの分子学に集中したこともお話ししました。分子が機能する場は細胞という単位ですから、分子細胞生物学、とも言います。業界聖書のような教科書のタイトルは、まさしく「Molecular Biology of the Cell(細胞の分子生物学)」です。表紙のイラストで、複雑な緑色がタンパク質分子で、白い帯は細胞膜を表しています。細胞膜にあるタンパク質分子が、クスリの標的として興味(と創薬ビジネス)の対象になっていることが、表紙にすでに明示されています。
Molecular Biology of the Cell(細胞の分子生物学)

さて、ここでCOGNANOが手に入れたアプローチをもう一度整理して見ます。
・超高速で変化し最適化コンテキストを持つゲノム → 遺伝子データ(ゲノム中で明示的な意味付けができる情報ウインドウは抗体遺伝子だけと言ってよい)
・計算資源 → 生きているアルパカ(オレゴンからの空輸に成功!)
・超高速で解読する技術 → 次世代シークエンサ(受託会社がたくさん稼働しているし、どんどん単価が安くなっている)
・・・・イケる!作戦は完璧じゃないでしょうか。しかし、実際に起こったことは停滞でした。苦い記憶ですが、このステップに初めて到達した5年前、ぼくたちは次世代シークエンサから吐き出される遺伝子データを前に思考停止していました。当たり前ですが、アルパカから得たデータは、atgc・・・・というアルファベットが何億文字も並んでいる行列でした。遺伝子がコードする抗体がアルパカの体内に実在し、標的タンパク質(抗原)に結合する親和性をもっていることは確実です。でも、どのくらいの強さでどの部分に結合し、どんな機能を持っているのかはわかりません。アルパカという生きた計算機は、どのような経過と判断で必要な抗体をリストしているのか、、、、そもそも人間が抗体を欲しがるのは「役に立つ物質=クスリ」になるからです。「遺伝子配列から有用性を推定できるようになる」しか解決策はありません。この時まで、このように大きなスケールの抗体遺伝子情報は存在しなかったので、当然ながら情報処理の方法論は存在しないわけです。このときの気分は、ドイツ機甲師団を待ち受ける連合国部隊のようなものだったでしょうか。エニグマ(ドイツ軍暗号)を解読しないと、全滅するかもしれない、、、、、もう一つの道は、従来のように、生物実験を実施して一つ一つの抗体クローンの機能を調べることです。頑張れば、1週間に100クローンか500クローンをチェックできるかもしれません。しかし、それだけはダメでした。手作業に戻れば、この研究を始めた意味を失ってしまう。
プログラムが必要らしいんですけど、、、
、、、、情けない話なのですが、こうなることはわかっていたはずなのに、データを見るまで「オレたちはやれる」と思っていたんですね。ときどきやってしまうんですが、遺伝子もタンパク質も抗体も扱えるエキスパートなので、「やれるゼ」になってしまったわけです。パソコンに、有用遺伝子を選ぶファンクションキーは付いてないという事実に気づくまで、しばらくかかりました。よほどボーッとしていたのでしょう。
どれくらい意識を失っていたでしょうか、あるとき「データ触っていいですか?」と声をかけてくれた人がいました。普段医師として働いているYさんでしたが、私生活ではプログラミングを趣味にしているということは聞いていましたので、「ああ、興味ありますか?いいよ、やってみて」と何気にデータを渡しました。どうせ宝の持ち腐れなのだから、試してもらうのは歓迎でした。自分がわかっている業界のことは評価できるけれど、違う領域については、誰にどんな能力があるかわかりません。誰にコンタクトしたら良いか、がわからないのです。トッププログラマーが周辺にいないことははっきりしていますし(というか会ったこともないし)、仮にコンタクトできても、基本的には、バイオマンはプログラムがわからず、エンジニアはバイオの言語がわかりません。「抗体と抗原の関係」について、いやその前に「遺伝子とはなにか」から、つまりゼロから説明しないと始まりません。プログラミングが好きすぎて生物研究に進んだ、というヒトは聞いたことがありません。
突破口はYさんが開いてくれました。数千万の抗体クローンを分類して、どのような親戚関係としてバンドルできるか、どの程度の結合強度と見込めるか、さらには、抗原表面のどのあたりに結合していそうか、、、、を、ウェット実験なしにカテゴライズしていったのです。こんなことができるなんて!「ま、これやりたくてアルパカ輸入したんですけどね」と冷静に言ったつもりでしたが、じつは踊り出したいくらいでした。アルパカ抗体遺伝子のデータを実験なしで評価できるプログラムが書けたことは重大な未来を示していました。コンピュータがクスリを予言できる時代が約束され、ぼくらにはその道筋が具体的に見えているわけです。ちなみに当時、仲間を集めようとして「一緒にやりませんか」とコンタクトした国内ベンチャーや企業には、うまく説明できなかったかもしれません。見たことも聞いたこともないコンセプトは、目の前でプレゼンしてもわからないのだ、ということが納得できるまで、また何年もかかりました。理由は簡単です。バイオとIT、両方わかる人が、世の中に(ほとんど)いないからです。ただし1チームだけ、興味を示してくれた海外企業があり、その企業とは現在共同研究を進めています。

アイアンドーム
もう2年前になりますが、パンデミックが始まった瞬間、ぼくらは新型コロナに舵をきりました。パンデミックまで(偶然にも)エイズウイルスを標的の一つにしていたので、RNAウイルスが急速に変異すること、どんな薬も早晩無力化されると予想していました。可能な限り素早くゲノム変異に追いすがり、追いつき、できることなら先回りして抗体効果を予言的中させたい、、、、人類はまだ、そのパスを構築していません。ゲノム変異(ウイルス)にはゲノム変異(抗体遺伝子)で対抗です。例えて言えば、ガザから発射される変則的なロケット弾を「着弾前に」撃ち落とす技に似ています。ミサイル火力よりむしろ、レーダー網とリアルタイム・マルチ対応、つまり情報能力の方が鍵になります。イスラエルがアイアンドームを開発できたのは、ITテックの力が大きかったと聞きます。ぼくらの腕を試すにはもってこいのチャンスです。このタイミングでバイオ創薬の仕組みを向上できるかもしれません。
もうひとつ、パンデミックでぼくが新たに注目したことは、医学以外のテーマ「社会運用」でした。コロナでわかったことは、
- 1滴のウイルスで人間社会を滅亡させられるリスクがある
- 迎え撃つにも、パーソナルな病気の側面と、社会安全保障の側面がある。両立はむずかしいとはいえ、上手にコントロールすることが文明社会には必須(成熟度のバロメータですらある)例えば世界で起きている「ワクチン拒否」は、バカにして済む話ではなく、人権や思想の問題にもなる。
- ウイルスは刻々と姿を変え、開発すれどもワクチンや薬は効かなくなる
- パンデミックは総じて、天災とか環境災害にちかい現象と理解した方がよく、治療学・医学以外の「社会運用」がさらに重要となる。
社会を安全に保つためには、無用な動線を排除し、隔離や医療を実効的に運用することが不可欠です。運用は、「いつ、どこで、だれが、どのような状態に」なっているのかを把握し、確度の高い予想を立てることから始まります。そのためには、変異ウイルスのタイプ、所在、量、時系列に関する可能な限りの細やかな情報を入手しなければなりません。ぼくがこのようなことを考えたのは、バイオに行き詰まったときに参考にした、「地球上のどんな地点でもリアルタイムに把握している地図」が頭にあったからに違いありません。でも残念なことに、Google mapには、今日もまだコロナウイルスの所在と量は掲載されていません。感染者数がPCR結果によって示されるだけです。(先進国の恵まれた場所だけで行われる)PCR検査数というバイアスデータではなく、地球上すべての場所でリアルタイムのバイオデータはとれないものか、、、、その開発もまた、バイオマンの義務だろうと思い、ある国内企業の賛同と支援を得てコロナ検査キットを作り始めました。どのみちクスリにする抗体をたくさん開発するのですから、検査にも使わなきゃもったいない、です。ウイルスをリアルタイムに数量化すれば、きっとITテックの人が見つけてくれて、「クラウド」という仕組みで、すごいことをやってくれるだろうと信じて、、、、
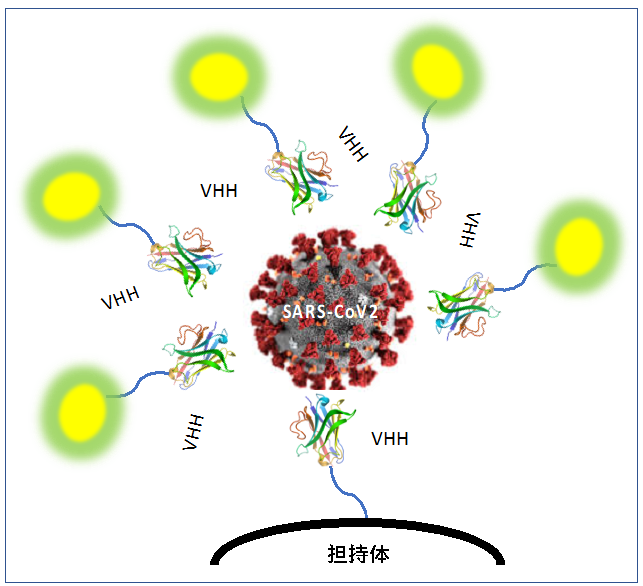
蛍光標識したVHH抗体でウイルスを検出する原理
エントリーが長くなりました。クラウドってどうやるんですか、IoTって何ですか、と聞いて回っている中で、ITエンジニアのまつもとりーさんと出会ったのは、パンデミックが始まって9ヶ月後です。この時には、すでに創薬シーズができていました。それから1年半たった今でも、(実験室レベルですが)オミクロン株に薬として効いていることはアナウンスしておきたいですね。そのような抗体は極めて稀ですから、、、、従来の職人芸を、アルゴリズムが追い抜いた!という自信を持てる結果です。この2年間は、まつもとりーさんに続いて機械学習エキスパートのつるべーさんの参加、海外ITテックとの共同研究、創薬シーズ開発成功、論文投稿、、、など、めまぐるしく時間が過ぎ、気づいたら、このようにブログを書くようになっています。この経過はまだ生々しいので、そのうち落ち着いて書かせていただこうと思います。
ハイブリッドチームができた!
現在、COGNANOは、バイオ班とAI班から成っています。バイオとAIのメンバーが共通言語を持てるようにする、というのが企業目標であり、データの質✖️量という強みを生かして、自動創薬のリーディングカンパニーになるのがビジョンです。さらに幸運にも、まつもとりーさんの相棒であるつるべーさんが、COGNANOの機械学習能力を劇的に向上させてくれています。新型コロナで、オミクロン変異以後を継続して追撃できるチームは、世界でも限られています。ぼくたちと同じようなアイデアを持っている会社が世界にあるかもしれません。競争するのか、協力するのか、、、、今後が楽しみです。

まつもとりー

つるべー
このブログに絡んでもらうといいのかな、と思い、次はバイオマンのまえださんに、書き継いでもらう予定です。引き続いて、まつもとりーさんには、IT系の目線で書いていただくことを期待しています。ぼく以外の目線で書いてもらうと、さらにCOGNANOのことをわかっていただけると思いますし、バイオがデータの時代に移行していることも(以前から予言はされていましたが)実感でわかっていただけると思います。長くなりましたが、ITエンジニアから視える景色に立ってみる(後編)を終わります。

アルパカの赤ちゃん。かわいい!!
ITエンジニアから視える景色に立ってみる(中編)
COGNANO テックブログA, No.3
COGNANOのいむらです。
前回から引き続き、ITエンジニアから視える景色に立ってみる(中編)です。
薬のもとになる物質はどこにある?
創薬の歴史で、理論だけでデザインされた例はまだありません。ゼロからの設計ができるほど、ぼくたちは生物のことを知りません。じゃあ生物に影響をあたえる物質(クスリ)はどこで探すべきでしょうか?太古から薬草(タバコや大麻もクスリです)やクマの肝をすり潰して薬に用いてきたのですが、人間が人工的な薬を作り始めたのは、ドイツ化学工業が発展した19世紀からでした。その後、発掘の対象は、地球上の生物に移ります。20世紀は、ジャングルで微生物を採集し、そこから抗生物質などを発見しようと努力した時代でした。このように、化学工場から、あるいは、自然から採集された候補物質のストックは、今では10億種類とも100億種類とも言われています。製薬会社は、大規模な化学ライブラリおよび抗体(ペプチド)ライブラリを保有し、その中から有効なシーズを掘り出すために日夜スクリーニングしています。
抗体を薬にするロジック
化学薬品に加え、この20年は抗体医薬が登場します。乳がん治療薬ハーセプチン、腫瘍免疫薬オプジーボによって、抗体の力でガンでさえ治癒できる、と知られるようになりました。どうして抗体は創薬に適しているのでしょうか?
生物は、個体→組織→細胞→分子→原子というスケールに分解できます。病気とは、個体が不調に陥っている状態の総称ですが、不調を改善する物質なら何でもクスリです。では、薬はどこに効くのでしょうか?クスリの本質は細胞への命令(コマンド)であり、コマンド受信は細胞の構成分子が担っています。ある分子だけに特定のコマンドを入力できる物質が「クスリ」で、多くの標的分子が知られる現代においては、抗体という物質が最有力候補です。なぜなら、標的分子に対する結合の特異性や強度にかんして、抗体以上に作りやすいツールはないからです。また、抗体という物質集団はもともと体内に存在しているので、毒性・副作用が低いことも強みです。その意味で、抗体は当面、薬の主役であり続けるでしょう。
とはいえ、抗体医薬が成立するためには、課題があります。
- 生物の抗体選択ルールがブラックボックスである
- 取得しにくい抗体が存在する(努力にもかかわらず成功していないフィールドがある:生物が回避しがちなのかも)
- 標的(エピトープ)を狙いたいが、デザインできない
- パンデミックのように標的が変異すると、抗体は無効化される
この限界を突破できるのか?可能だとすれば、どうすれば抗体能力を引き出せるか?そもそも生物はどのくらいの抗体作成能力を持っているのでしょうか、、、
前回のブログで、「手仕事でバイオデータを極めるには400万年かかるのね」という弱音を吐いたのですが、じゃあ抗体は、400万年分のデータを取得する方法になりえるでしょうか?
生物の演算能力を数量化してみる
ヒトやアルパカなど大型の哺乳類は40兆個の細胞からなり、抗体を作るリンパ球は1兆個あります。単純化するため、1兆個の細胞が抗体遺伝子組み換え(体細胞ハイパーミューテーション)を起こすと考えます。最速で1日2回の変異が導入され、抗体が完成すると考えられる2ヶ月という期間には、120回の変異が出現します。1兆個(1012)の細胞が分裂するたびに、2の120乗回の変異チャンスがあります。2の120乗(〜1036)の1兆(1012)倍は、1048のチャンスです。
別の角度から考えます。抗体の最適化は、アミノ酸50個程度の超可変領域を変異対象とします。アミノ酸は20種類存在するので、理論可能性は、2050通り(=1x1065)の組み合わせです。1065通りの可能性のうち1048回、体内で遺伝子変異を起こしてみると言うリアルトライアルを通して、ぼくたちの体内で最適解に至っていると解釈できます。これは生物が行う最適化演算であり、プロセスはブラックボックスであるが、長い進化の歴史から、さまざまな安全装置が作動する成熟した計算システムであると考えられます。自己に不利な変異は排除する、役に立たないような配列(たとえば立体構造を取らない配列とか、同じアミノ酸が延々続くとか)はそもそもトライしない、などのアルゴリズムを持っているにちがいありません。この選択システムで有用と判断されなければ、分裂停止し淘汰されます。ヒトのからだは1013~14の細胞サイズなので、本当に必要な抗体産生細胞しか収容できませんし。
アルパカVHHシステムを使った方法の強みを、ぼくたちはこう考えています。
- →抗体選択プロセスを電子情報としてトレースすればよい
- →抗体変異は確率的なので、膨大な遺伝子情報を保管し、有用性を解析するシステムがあればよい
- →特定の標的領域に結合する抗体群を炙り出す計算手法を開発すればよい
- →変異にかかわらず普遍性を期待できる抗体を予見し選択する方法を見つければよい
このようなシステムで、取得困難だったシーズを超高速に出せるはずです。生体の免疫システム(最適化演算)情報は、だから、ロジックベースの抗体デザインへの早道であると考えています。試験管内の抗体チェックは人工的でノイズが多く、生体内での標的分子との相互作用とは結果がかなり異なります。その意味でも、アルパカの体内でリアルで起きたことは、ぼくたちの体のなかでも再現されるはずです。だから、ぼくたちにとって、アルパカは単に動物ではなく、最適かつ精度の高い探索プローブをほとんど無限に情報化してくれる「生きた超高速演算マシン」なのです。給電は必要なく、干し草と水で満足して24時間計算を続けてくれています。
長くなってすいません、中編ここまで、後編に続きます。
ITエンジニアから視える景色に立ってみる(前編)

COGNANOテックブログA, No.2
COGNANOのいむらです。
、、、、どうしてアナタはCOGNANOを立ち上げたの?という質問をいただき、考えてみました。最初のきっかけは25年前、実行にうつしたのが10年前です。今回は、その話をさせてください。
研究テーマの変遷
ぼくは医者をしたあと、博士課程に入り、がん制御の研究を開始しました。4年の期限内に論文を出せましたが、あの重労働は2度とできないと思います。生まれつき健康だったので、壊れないで済みました。バイオの研究は、おおむね、「XXXという現象はOOOという分子の機能により起こる」という形式になります。→生物の基盤になる機能物質単位は分子ですよね、、、、OOOという分子が原因でXXXが起きているんだよね、、、、だから、このOOO分子に影響を与えると病気を治せたりするかもね、、、、というシナリオです。影響を与える物質として、最有力で使いやすい分子が抗体です。ぼくは抗体という分子ツールを自分で開発することで、薬を作る筋道を意識したわけです。同時に、恐ろしいことに気づきました。当時はまだヒトのゲノムが解読されてなかったのですが、莫大な数の遺伝子が存在することだけは判っていましたので、「1分子の証明に4年かけてしまった、もし対象分子が100万個あったら、400万年研究することになるのか、、、、」それが25年前です。
The human OX40/gp34 system directly mediates adhesion of activated T cells to vascular endothelial cells. A. Imura, et al. 1996 May 1;183(5):2185-95. doi: 10.1084/jem.183.5.2185.
どうしてもうまいやり方がわからず、「老化研究」のラボに移りました。このとき考えていたのは、「遺伝子やタンパク質などの分子を対象にする以外に、具体的なバイオ研究の方法はみつかっていない。しかし、知りたいことは物質ではなく、産まれて生きて死ぬ、って何だろう?だ。どうしたら両方をコネクトできるんだろう?」その時にイメージしていたのは、(仮に対象分子が100万種類あるとしたら)100万軒の街を空から眺めつつ、同時に、一軒一軒の家の内部も(ファミリーの顔や名前だけじゃなく、靴下の種類や暖炉の燃え方に至るまで)詳細に理解する、という認識は人間に可能か?ということでした。まったく方法が思いつかず、「ああ、ぼんやり街を眺めて、諦めることになるかもね、、、」という気持ちを抱えて、あえてファジーなテーマにトライしてみようとしたのでした。物質である分子を気にしつつ、分子で説明できなさそうなコンテキストに逆張りした、といえるでしょうか。とはいうものの、この時代の老化研究は物質主義に足場があり、分子学を超えた成果には至りません。
alpha-Klotho as a regulator of calcium homeostasis. A. Imura, et al. 2007 Jun 15;316(5831): 1615-8.doi: 10.1126/science.1135901.
どうしたって、近くを見ると遠くは見えず、遠くを見ると近くは見えない。しかし今はなんとか説明できます。100万軒どころか、地球の全表面の写真を瞬時に見せてくれ、1軒ごとの住所まで知る方法が出現したからです。
https://www.google.co.jp/intl/ja/earth/
出典:google earth
バイオデータの問題
これを、分子や細胞のナノ世界でやれば良い、と、今ならわかります。ただバイオ界の問題は、比較的解読しやすい遺伝子情報を除き、タンパク質、脂質、糖鎖に関して部分的な情報しか登録されておらず、高速処理したくても対象データが少ないということでした。「まともにやれば400万年かかるデータ」の蓄積をしないと話がはじまらないという、にわとりタマゴ問題です。
ミレニアム紀に合わせたように、2000年にヒトゲノムが全解読され、およその対象分子数(バイオ界にどれくらいのファミリー数が存在するか)が予想できるようになりました。
出典:The Human Genome Project by NHGRI
実際には、基本的なタンパク質数は約3万、バリエーションを許しても30万程度、修飾とか複合体を合わせても1〜2桁上のエレメント情報が、バイオ世界の情報サイズであることが想像できるようになりました。アプローチの方法は後で考えるとして、バイオマン的には、まずデータ蓄積だろ、、、、じゃあ、どんなデータがどのくらいあればいいというのか?これに関しては、データエキスパートでありリアリティ思想家、まえださんの意見が最も正確でしょう。このあたり、後日述べてもらおうと思います。

前列左がまえださん 後列は京大インターン(左から、こばやしさん、しみずさん、かさいさん、いしださん)
さきほど、空から地表を撮影し、個人情報まで知悉しているシステムが登場した、と書きました。スマホで何かが起きている、ということは、うすうす知っていましたが、当時はつながりを想像できませんでした。結局、テックピープルに繋がらないと無理だ、と判断したのは、アルパカからのデータスケールが「バイオマンが見たことがないサイズ」だったことで、呆然となったからです。
変わらないゲノムと変わるゲノム
産まれてから死ぬまで、生物の遺伝子(ゲノム)は変わりません。もし変わるということがあれば、それは別の自分になるということです(例えばガンなど)。ただし、適切な目的で変わる場所が1箇所だけあります。それが抗体遺伝子です。抗体だけは、無数の侵入物に対して、ほとんど無限に遺伝子を変化させて対抗します。そのために、ゲノムの一部分が積極的に変化するようにデザインされています。だからこそワクチンを打てば、体の中で抗体ができてくるのですが、その原理解明は、利根川氏と本庶氏の功績であることは広く知られています。一方、まったく独立に、約30年前、ベルギーのヘイマー氏という研究者が、ラクダの抗体は非常にシンプルで、コードする遺伝子を容易に読むことできると、偶然気づきました。ぼくたちは、論文でラクダ抗体のことを知り、かすかなサインを聞き取った気がしました。ちょうど2010年ごろ出現してきた「次世代シーケンサー」という遺伝子解読マシンを使って、抗体遺伝子を超高速で読み取り、標的に結合するかしないかで、機能分類するという技術を独自に開発していきました。
Naturally occurring antibodies devoid of light chains C. Hamers-Casterman, et al. Nature volume 363, pages446–448 (1993)
この技術による「ナノ(NANO)王国100万軒の包括的かつ徹底的な調査」に向けて、2014年にCOGNANOをローンチしました。どの部分がビジネスになるのかはっきりわからない状態でのローンチだったので、他人や国の予算を頼ることはできず、家内が経営している街場の薬局からの資金を頼りにラボを立ち上げ、会社登記を済ませました。この時から、バイオマンが分野違いのITエンジニアに辿り着くまでには何年もかかるのですが、それは(中編)で書きたいと思います。
ITエンジニアから視える景色に立ってみる(中編)に続く
生物をデジタルリソースとして認識する
COGNANO テックブログA
はじめまして、バイオテックCOGNANOのいむらです。
7年前に会社を立ち上げて、研究に必要なアルパカを買おうとしたのですが、日本で売ってくれるところがなくて、オレゴンに買い付けに行きました。動物輸入は両国政府の交渉が必要で、何回もアメリカに行き、18頭をジャンボジェットに乗せて輸入したのが2016年。今では、30頭に増えました。なんでアルパカ?その理由がわかっていただければ、このブログを読んでいただく甲斐があるというものです。よろしくお願いいたします!

このあと、ジャンボジェットに乗せられ成田へ向かいます。
変異ウイルス を捕まえる抗体デザイン
パンデミックで、ワクチン、抗体という単語が身近になっています。ウイルスタンパク質を体内で発現させるモデルナやビオンテックのRNAワクチンが実用化され、世界中で接種されるようになりました。重症になれば(なる前に)、ウイルスを抑える抗体製剤が投与されます。回復した患者のリンパ球から抗体遺伝子を読み取り、薬品化します。ただ、欠点もあります。まず、患者サンプルから材料を取るので、感染者が資源として大量に必要であること(今回は十分集まりました)、また、ウイルスが急速に変異するので、時間とともに通用しなくなること、の2つの問題です。一方、ワクチンを打てば抗体ができて感染をブロックできますが、ウイルスは変異して抗体から逃れようとします。ヒトが、ワクチンという方法で、ウイルスの進化を助けている(誘導している)という一面があります。ワクチン、抗体医薬、両方とも「過去の」ウイルスには対応できますが、未来に対応できないのがネックです。
そこで、どんなにウイルスが変異しても必ず狙撃できるシステムが必要です。そのためには、過去の患者のデータではなく、標的を先回りして予想するロジックが必要になります。とはいうものの、タンパク質の形(3D構造)は難しく、簡単に予想できるものではありません。最近、Google傘下のDeepMindというベンチャーが3D構造を予想するプログラムAlphaFold2を開発したニュースが流れましたが、これは文句なく歴史的偉業だと思われます。ただ話は、まだ終わりません。3D構造がわかっても量子論的な確率で振動する標的に「当てる」ワザは簡単ではなく、標的に結合する物質をデザインするテクノロジーは存在しません。とはいえ、AlphaFold2のような情報ツールを使って、医薬デザインが進化していくのは間違いないでしょう。そこで、アルパカの生物演算パワーが必要になるのですが、、、この話を、これからブログで書いて行きます。
「6年解けなかった構造があっさり」──タンパク質の“形”を予測する「AlphaFold2」の衝撃 GitHubで公開、誰でも利用可能に - ITmedia NEWS
グーグルの親会社アルファベットがAIを活用して創薬に挑むIsomorphic Labsを設立 | TechCrunch Japan
COGNANOのビジネス
COGNANOのビジネススタイルは、バイオチームがアルパカを使って生み出すデータが畑です。豊穣な畑から、エンジニアチームが「情報という果実」を摘み取ります。それをプロダクトにしていくのですが、最終的には薬として、あるいはIoTとしてのパーソナルヘルスケアを世の中に届けられたらいいな、と思っています。バイオチームのリーダーは、遺伝子工学、生化学の第一人者まえださん、エンジニアチームはマシンラーニング(ML)のエキスパート、やまざきさん、つるべさんです。まつもとりーさんはプロダクトマネージメントやエンジニア組織・環境作り、技術広報などITに関わる全体的な技術顧問です。いむらはセールス&広報という位置付けでしょうか。京大の大学生、院生が、6名、インターンとして仕事をしてくれています。順番に、ブログを書いていってもらいますので、ご期待ください。

いむら
まつもとりー
生物を情報で捉える
この150年、バイオは物質主義をベースに急発展してきました。小分子を対象とする無機化学・有機化学、やがて高分子まで対象とする生化学となり、遺伝子の発見に始まった遺伝子工学、最近では移植や再生、遺伝子治療などに派生しています。しかし今のところ、バイオマンから発信されている範囲は物質主義を出ず、生き物の構成因子(タンパク、糖、遺伝子、脂質、および複合体としての細胞)が対象になっていることは変わりません。これらの構成因子を、どのように研究し開発に役立てましょうか、という発想自体は150年変わっていない、、、でもその結果、1万個の候補から1個の薬さえできない時代に突入してしまいました。巨額の開発原資を回収するために、患者あたりの治療費が1億円かかることは珍しくなく、その資本サイクルはメガファーマしか回せません。研究者の能力とは無関係に、大資本しか薬を作ることができない世界になりました。その結果、全てのコロナ薬が海外の巨大メーカーから輸入されていることはご存知の通りで、なんだか居心地わるくないですか、、、
COGNANOが目指しているのは、生物を情報で捉えようとするベクトルです。人間の認識で理解できるほど生物は簡単ではない、という事実を(元バイオマンとして悔しいのですが)受け入れることから、再出発したのがCOGNANOの立場です。具体的には、
- 存在自体が未知だった新規ガン細胞マーカー30種類を、一回の実験データから発掘
- 新型コロナが変異しても効き続ける治療薬シーズを1年以上前に準備
という成果を上げています。これから、順番に論文にしてお知らせしますので、お楽しみに!
生物を情報集合体として捉え「バイオとITで世界の見え方を変える」、、、ヒトの認識限界を突破することがCOGNANOのミッションです。ベンチャーとしてのプロダクトは、薬シーズであったりヘルスモニタリングであったりします。しかしエンジンは情報でありアルゴリズムです。すでに脈拍や血圧はスマートウオッチでモニターされていますが、単に数値をクラウドに上げるという話ではなく、分子ベース、細胞ベースの多次元情報をパーソナル、リアルタイムにアップロードし、ぼくらが生きている時間を安全でハッピーにするインフラにしようとしています。ですから、バイオモニタリングの原理と、アプリケーションであるIoTの両方が、ともにアルゴリズムの話になります。そのために、バイオマンとITエンジニアが接近し、共通言語で考え、作業できる場が必要でした。それがCOGNANOです。つまりこのブログは、「生きているってアルゴリズムだったんだ」をおはなしする広場です。並行して、テックブログシリーズBは、もっと個人的な目線でお話していきますので、よかったらそちらも覗いてみてください。では、次回に続きます!